7/18に大蔵海岸でBBQを行いました。
前期の締めくくりにみんなで楽しむことができました。




イベント係の皆さん、準備していただきありがとうございました。
7/18に大蔵海岸でBBQを行いました。
前期の締めくくりにみんなで楽しむことができました。
イベント係の皆さん、準備していただきありがとうございました。
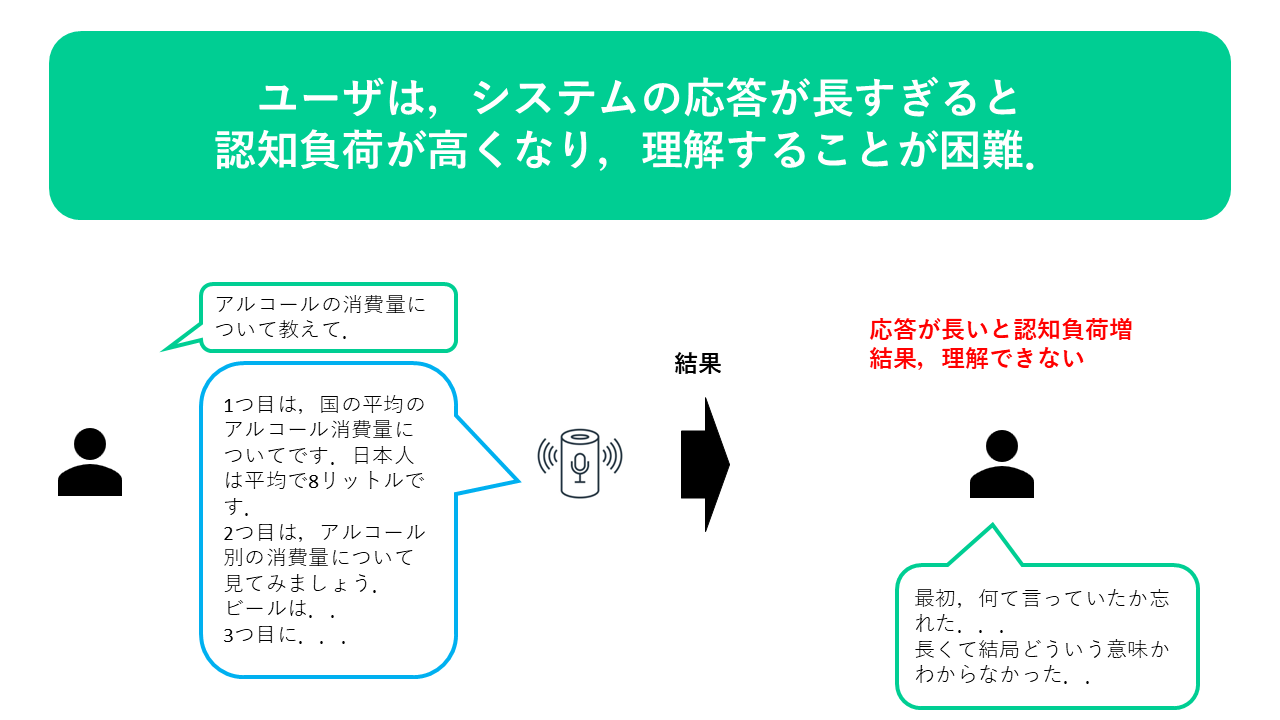
本研究では,音声のみでシステムとユーザが検索を行う音声対話型検索におけるシステムの応答の長さとユーザの検索行動の関係について調査する.音声対話型検索では,長い応答はユーザの認知的負荷が高く,特に比較や意思決定を伴うような複雑な検索タスクにおいてはその影響は大きいと考えられる.そこで本研究ではシステムが応答を端的に要約して応答する短応答型提示を提案する.実験のため,既存のAPIを利用し実世界のおける音声対話と近い形で音声対話型検索を可能とするシステムを構築した.実験では,通常の長い応答をユーザに返すシステムと,短い応答を返す提案システムの2つを用いて実験参加者に検索を行ってもらった.また,検索タスクの複雑性と応答の長さとの関係を明らかにするため,複雑な検索タスクと簡単な検索タスクで実験を行った.実験の結果,短い応答を返す提案システムの方が,検索タスクの複雑さによらずユーザ認知的負荷が減少する傾向にあり,その結果,タスクのサマリ結果にシステムから得た情報を多く含んでいることが明らかになった.一方で,ユーザのサマリ内容は,長い応答を返すシステムよりも考察や分析の質において劣る傾向にあった.ユーザのクエリを分析した結果,探索的検索を促すために,初期段階で広範囲に情報を提示するシステム応答戦略の必要性が示唆された.
飛岡 憲,山本 岳洋,大島 裕明:音声対話型検索におけるシステムの応答の長さが検索行動へ与える影響の分析
第17回データ工学と情報マネジメントに関するフォーラム(DEIM2025), 3E-02, 2025年3月.

本研究では,日本語における音韻の類似性に基づく言葉遊びの一形態である駄洒落に注目し,対話型駄洒落の生成手法を提案する.駄洒落とは,同一または非常に類似する音韻を持つ言葉を用いて遊ぶ言語的な遊戯であり,文中に音韻が類似する単語の集合が存在することによって特徴づけられる.本研究のアプローチは,ユーザから任意のテキスト(発話文)を受け取り,その中から特定の単語の音韻に類似する単語やフレーズを用いて,発話に対する面白い応答(返答文)を生成するものである.提案手法は,検索と生成,ランキングの3 つのステップから構成されている.まず,検索のステップでは,音素の類似性に基づいて音韻が類似する単語やフレーズを検索する.次に,生成のステップでは,得られた単語やフレーズを返答文に含めるような制約を課したプロンプトを大規模言語モデルに入力することにより,対話型駄洒落の制約を満たした返答文の候補を生成する.最後のランキングのステップでは,生成された返答文の候補を対話の自然らしさでランキングし,もっとも自然な返答文を出力として採用する.評価実験では,人手による評価を通じて,生成された返答文が対話型駄洒落として適切かを評価した.
Wang Yilin, 山本岳洋, 大島裕明: 音素の類似性による対話型駄洒落の生成, 第17回データ工学と情報マネジメントに関するフォーラム(DEIM2025), 8H-02, 2025年3月.
情報検索に関するトップカンファレンスであるThe 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2025) において,山本准教授が Excellent PC members に選ばれました.
参考: Claudio Pomo氏のX上のポスト
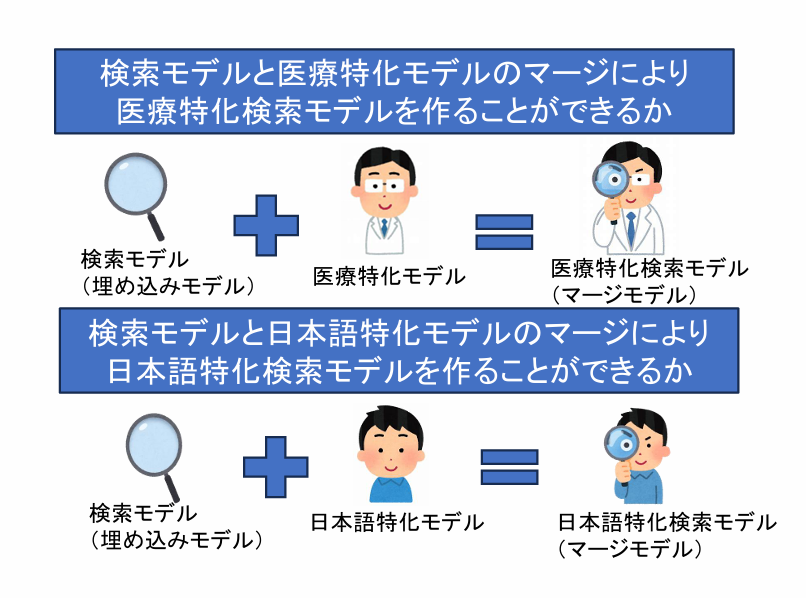
本研究では,アドホック検索タスクにおけるモデルマージの有効性について検証する.モデルマージは,複 数のモデルの異なる特性を組み合わせて基盤モデルを構築し,計算コストを抑えつつ性能を向上させる手法として注 目されている.我々は,モデルマージをアドホック検索タスクに適用することで,短時間かつ低コストで検索モデル の性能を向上させられると考えた.そこで本研究では,検索タスクに対応するようファインチューニングされたモデ ルと,検索能力は持たないが特定のドメインに特化するように継続事前学習されたモデルを重みレベルで線形にマー ジし,医療および日本語ドメインにおける文書検索性能への影響を調査した.実験の結果,モデルマージによって検 索性能が向上するケースが確認され,特に検索モデルの重みに比重を置いた場合に高い性能が得られる傾向が見られ た.この結果は,アドホック検索タスクへのモデルマージの適用可能性を示唆し,低コストかつ高性能なドメイン特 化検索モデルの構築に貢献するものと考えられる.
佐々木泰河, 山本岳洋, 大島裕明, 藤田澄男: アドホック検索タスクにおけるモデルマージの効果検証, 第17回データ工学と情報マネジメントに関するフォーラム(DEIM2025), 1E-05, 2025年3月.